字典树:Trie
针对特定类型的搜索而优化的树数据结构。当你想要获取部分值并返回一组可能的完整值时,可以使用Trie。典型的例子是自动完成。
特点:
- key都为字符串,能做到高效查询和插入,时间复杂度为O(k),k为字符串长度
- 缺点是如果大量字符串没有共同前缀时很耗内存。
- 它的核心思想就是减少没必要的字符比较,使查询高效率。
- 即用空间换时间,再利用共同前缀来提高查询效率。
字典树的应用
只要你想要将前缀与可能的完整值匹配,就可以使用Trie。
- 自动填充/预先输入
- 搜索
- 输入法选项
- 分类
- IP地址检索
- 电话号码
字典树的实现
class PrefixTreeNode {
constructor(value) {
this.children = {};
this.endWord = null;
this.value = value;
}
}
class PrefixTree extends PrefixTreeNode {
constructor() {
super(null);
}
// 基础操作方法
// 创建一个节点
addWord(string) {
const addWordHelper = (node, str) => {
if (!node.children[str[0]]) {
node.children[str[0]] = new PrefixTreeNode(str[0]);
if (str.length === 1) {
node.children[str[0]].endWord = 1;
} else if (str.length > 1) {
addWordHelper(node.children[str[0]], str.slice(1));
}
};
addWordHelper(this, string);
}
}
// 预测单词
// 即:给定一个字符串,返回树中以该字符串开头的所有单词。
predictWord(string) {
let getRemainingTree = function(string, tree) {
let node = tree;
while (string) {
node = node.children[string[0]];
string = string.substr(1);
}
return node;
};
let allWords = [];
let allWordsHelper = function(stringSoFar, tree) {
for (let k in tree.children) {
const child = tree.children[k]
let newString = stringSoFar + child.value;
if (child.endWord) {
allWords.push(newString);
}
allWordsHelper(newString, child);
}
};
let remainingTree = getRemainingTree(string, this);
if (remainingTree) {
allWordsHelper(string, remainingTree);
}
return allWords;
}
// 打印所有的节点
// 通过在空字符串上调用predictWord来打印Trie中的所有节点。
logAllWords() {
console.log('------ 所有在字典树中的节点 -----------')
console.log(this.predictWord(''));
}
}
散列表(哈希表):Hash Tables
哈希表是什么?
散列(hashing)是电脑科学中一种对资料的处理方法,通过某种特定的函数/算法(称为散列函数/算法)将要检索的项与用来检索的索引(称为散列,或者散列值)关联起来,生成一种便于搜索的数据结构(称为散列表)。也译为散列。旧译哈希(误以为是人名而采用了音译)。
它也常用作一种资讯安全的实作方法,由一串资料中经过散列算法(Hashing algorithms)计算出来的资料指纹(data fingerprint),经常用来识别档案与资料是否有被窜改,以保证档案与资料确实是由原创者所提供。 —-Wikipedia
哈希表的构成
Hash Tables优化了键值对的存储。在最佳情况下,哈希表的插入,检索和删除是恒定时间。哈希表用于存储大量快速访问的信息,如密码。
哈希表可以概念化为一个数组,其中包含一系列存储在对象内部子数组中的元组:
{[[['a',9],['b',88]],[['e',7],['q',8]],[['j',7],['l ',8]]]};
- 外部数组有多个等于数组最大长度的桶(子数组)。
- 在桶内,元组或两个元素数组保持键值对。
哈希表的基础知识
这里我就尝试以大白话形式讲清楚基础的哈希表知识:
散列是一种用于从一组相似对象中唯一标识特定对象的技术。我们生活中如何使用散列的一些例子包括:
- 在大学中,每个学生都会被分配一个唯一的卷号,可用于检索有关它们的信息。
- 在图书馆中,每本书都被分配了一个唯一的编号,可用于确定有关图书的信息,例如图书馆中的确切位置或已发给图书的用户等。
在这两个例子中,学生和书籍都被分成了一个唯一的数字。
假设有一个对象,你想为其分配一个键以便于搜索。要存储键/值对,您可以使用一个简单的数组,如数据结构,其中键(整数)可以直接用作存储值的索引。
但是,如果密钥很大并且无法直接用作索引,此时就应该使用散列。
一个哈希表的诞生
具体步骤如下:
- 在散列中,通过使用散列函数将大键转换为小键。
- 然后将这些值存储在称为哈希表的数据结构中。
- 散列的想法是在数组中统一分配条目(键/值对)。为每个元素分配一个键(转换键)。
- 通过使用该键,您可以在O(1)时间内访问该元素。
- 使用密钥,算法(散列函数)计算一个索引,可以找到或插入条目的位置。
具体执行分两步:
- 通过使用散列函数将元素转换为整数。此元素可用作存储原始元素的索引,该元素属于哈希表。
- 该元素存储在哈希表中,可以使用散列键快速检索它。
hash = hashfunc(key)
index = hash % array_size
在此方法中,散列与数组大小无关,然后通过使用运算符(%)将其缩减为索引(介于0和array_size之间的数字 - 1)。
哈希函数
- 哈希函数是可用于将任意大小的数据集映射到固定大小的数据集的任何函数,该数据集属于散列表
- 哈希函数返回的值称为哈希值,哈希码,哈希值或简单哈希值。
要实现良好的散列机制,需要具有以下基本要求:
- 易于计算:它应该易于计算,并且不能成为算法本身。
- 统一分布:它应该在哈希表中提供统一分布,不应导致群集。
- 较少的冲突:当元素对映射到相同的哈希值时发生冲突。应该避免这些。
注意:无论散列函数有多健壮,都必然会发生冲突。因此,为了保持哈希表的性能,通过各种冲突解决技术来管理冲突是很重要的。
良好的哈希函数
假设您必须使用散列技术{“abcdef”,“bcdefa”,“cdefab”,“defabc”}等字符串存储在散列表中。 首先是建立索引:
- a,b,c,d,e和f的ASCII值分别为97,98,99,100,101和102,总和为:597
- 597不是素数,取其附近的素数599,来减少索引不同字符串(冲突)的可能性。
哈希函数将为所有字符串计算相同的索引,并且字符串将以下格式存储在哈希表中。
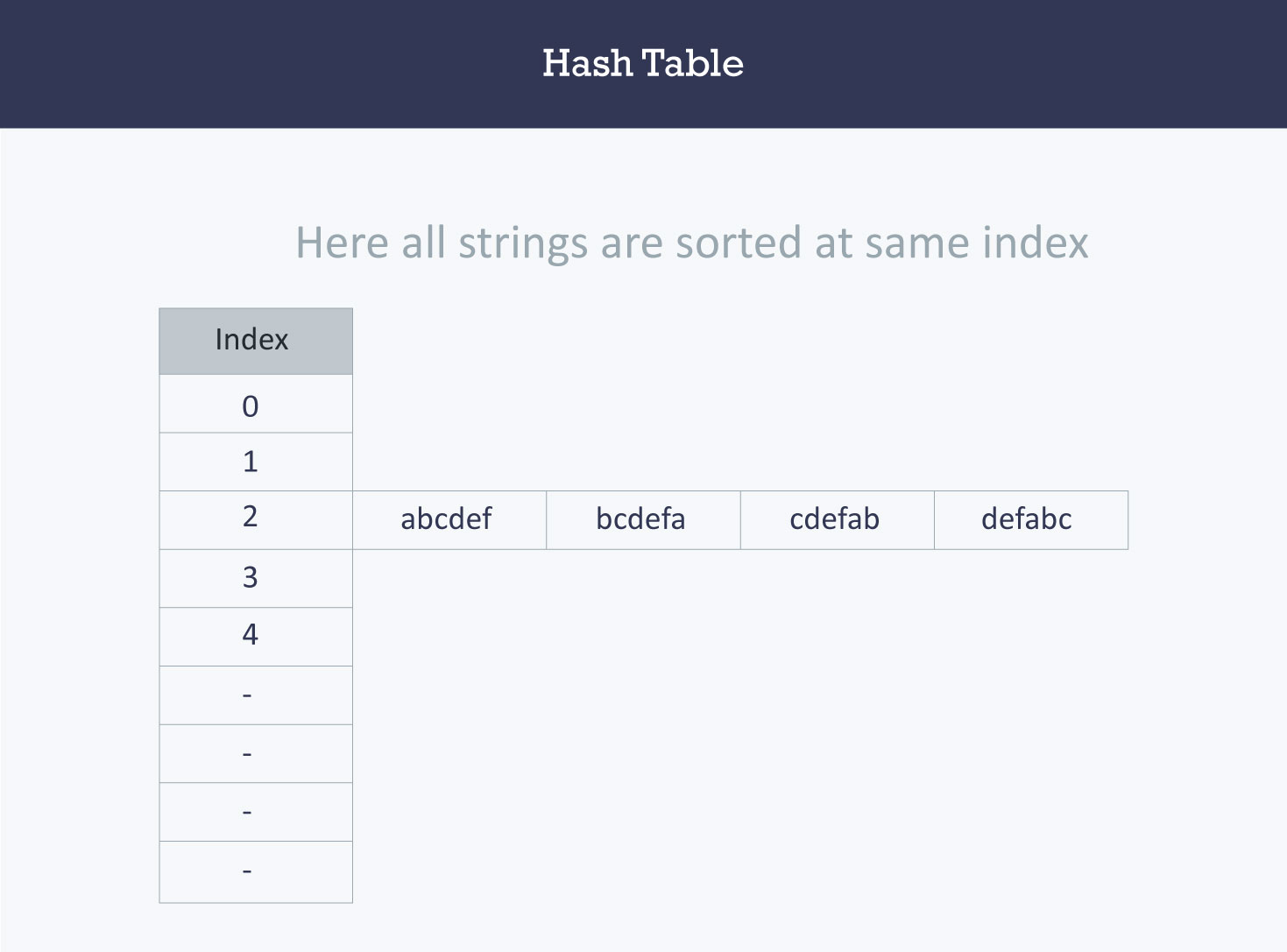
由于所有字符串的索引都相同,此时所有字符串都在同一个“桶”中。
- 这里,访问特定字符串需要O(n)时间(其中n是字符串数)。
- 这表明该哈希函数不是一个好的哈希函数。
如何优化这个哈希函数?
注意观察这些字符串的异同
{“abcdef”,“bcdefa”,“cdefab”,“defabc”}
- 都是由a,b,c,d,e和f组成
- 不同点在于组成顺序。
来尝试不同的哈希函数。
- 特定字符串的索引将等于字符的ASCII值之和乘以字符串中它们各自的顺序
- 之后将它与2069(素数)取余。
字符串哈希函数索引
| 字符串 | 索引生成 | 计算值 |
|---|---|---|
| abcdef | (97 1 + 98 2 + 99 3 + 100 4 + 101 5 + 102 6)%2069 | 38 |
| bcdefa | (98 1 + 99 2 + 100 3 + 101 4 + 102 5 + 97 6)%2069 | 23 |
| cdefab | (99 1 + 100 2 + 101 3 + 102 4 + 97 5 + 98 6)%2069 | 14 |
| defabc | (100 1 + 101 2 + 102 3 + 97 4 + 98 5 + 99 6)%2069 | 11 |
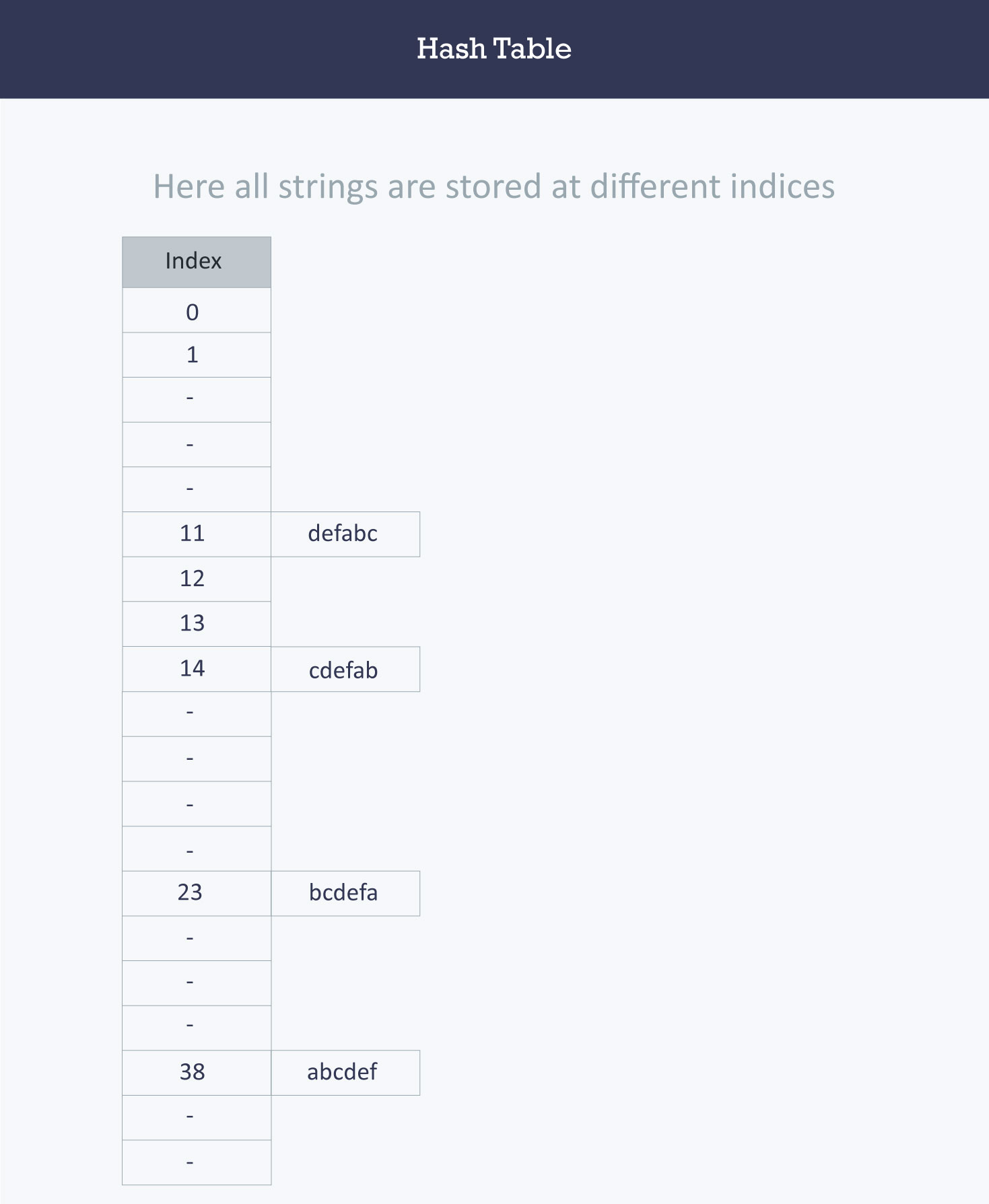
在合理的假设下,在哈希表中搜索元素所需的平均时间应是O(1)。
哈希表的实现
class Node {
constructor( data ){
this.data = data;
this.next = null;
}
}
class HashTableWithChaining {
constructor( size = 10 ) {
this.table = new Array( size );
}
// 操作方法
// 素数判断
isPrime( num ) {
for(let i = 2, s = Math.sqrt(num); i <= s; i++)
if(num % i === 0) return false;
return num !== 1;
}
// 哈希函数生成
computeHash( string ) {
let H = this.findPrime( this.table.length );
let total = 0;
for (let i = 0; i < string.length; ++i) {
total += H * total + string.charCodeAt(i);
}
return total % this.table.length;
}
// 取模
findPrime( num ) {
while(true) {
if( this.isPrime(num) ){ break; }
num += 1
}
return num;
}
// 插入值
put( item ) {
let key = this.computeHash( item );
let node = new Node(item)
if ( this.table[key] ) {
node.next = this.table[key]
}
this.table[key] = node
}
// 删除值
remove( item ) {
let key = this.computeHash( item );
if( this.table[key] ) {
if( this.table[key].data === item ) {
this.table[key] = this.table[key].next
} else {
let current = this.table[key].next;
let prev = this.table[key];
while( current ) {
if( current.data === item ) {
prev.next = current.next
}
prev = current
current = current.next;
}
}
}
}
// 判断包含
contains(item) {
for (let i = 0; i < this.table.length; i++) {
if (this.table[i]) {
let current = this.table[i];
while (current) {
if (current.data === item) {
return true;
}
current = current.next;
}
}
}
return false;
}
// 判断长度或空
size( item ) {
let counter = 0
for(let i=0; i<this.table.length; i++){
if( this.table[i] ) {
let current = this.table[i]
while( current ) {
counter++
current = current.next
}
}
}
return counter
}
isEmpty() {
return this.size() < 1
}
// 遍历
traverse( fn ) {
for(let i=0; i<this.table.length; i++){
if( this.table[i] ) {
let current = this.table[i];
while( current ) {
fn( current );
current = current.next;
}
}
}
}
}
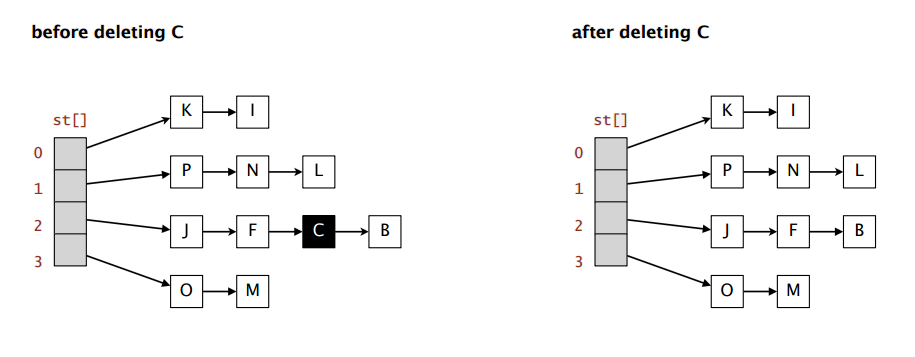
最后放张哈希表的执行效率图

删除值前后demo